


Shakin uusi aikakausi alkoi joulukuussa 2017 kun Google¹ järkytti shakkimaailmaa julkistamalla täysin uudenlaisen ”tekoälyyn” pohjautuvan shakkitietokoneen, joka oli omin avuin oppinut lajin hienoudet kirjaimellisesti yön yli. Syntyi AlphaZero, uusi shakkitietokone, joka välittömästi pyyhki lattiaa Stockfishillä voittaen sen ensimmäisessä 100 pelin ottelussa täysin ylivoimaiseen tyyliin (28 voittoa, 72 tasapeliä, 0 tappiota). Vastaava tulos toistui vuotta myöhemmin eri ajoilla ja erikoissäännöillä pelatussa tuhannen pelin ottelussa. Uusi aikakausi shakkitietokoneiden ja kenties koko pelin historiassa oli alkanut.
(¹ AlphaZero on brittiläisen DeepMind yhtiön kehittämä. Googlen emoyhtiö Alphabet osti DeepMind -yhtiön vuonna 2014.)
Mutta mitä itse asiassa tämä muutos tarkoittaa laajemmassa kuvassa? Millä tavalla ”uusi” eroaa ”vanhasta”? Tarkoittaako ”uusi” ainoastaan kertaluokkaa tehokkaampaa shakillista suorituskykyä tietokone vs. tietokone -kilpailussa, vai onko ”uudella” jotain annettavaa myös meille ihmispelaajille? Ovatko shakkitietokoneet saavuttaneet jo täydellisen tason ihmispelaajien apuvälineinä, vai ovatko jotkin ihmispelaajien tarpeet tai toiveet edelleen ratkaisematta?
Tämä artikkeli tutkii ja pohtii AlphaZeron käynnistämää shakkimaailman mullistusta kolmesta näkökulmasta:
- Mitä konkreettista uutta AlphaZero toi shakkitietokoneiden maailmaan?
- Voiko AlphaZero tarjota ihmispelaajille uusia strategisia ideoita ja muuttaa ihmisten käsitystä parhaasta tavasta pelata shakkia?
- Mitkä ihmispelaajien käytännön ongelmat ovat edelleen ratkaisematta ja mitä ratkaisuja shakkitietokoneet voisivat tulevaisuudessa tarjota?
1. Mitä konkreettista uutta AlphaZero toi shakkitietokoneiden maailmaan?
AlphaZero esiteltiin ”tekoälyyn” perustuvana shakkitietokoneena, joka oppi kaiken shakista vain muutaman tunnin itseopiskelun tuloksena, saatuaan lähtötiedoksi ainoastaan pelin säännöt. Mitä tämä kaikki konkreettisesti tarkoittaa? Mitä tapahtui noiden muutaman tunnin aikana? Millainen kone syntyi tuon harjoittelun tuloksena, joka kykeni voittamaan shakkitietokoneiden hallitsevan kuninkaan Stockfishin näytöstyyliin?
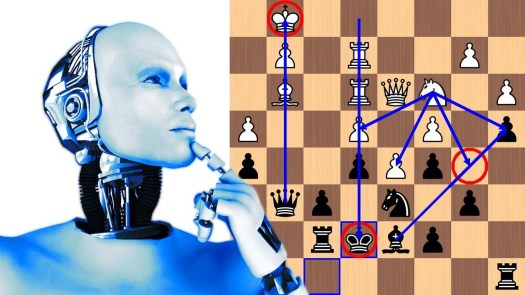
Kaikki shakkitietokoneet, uudet ja vanhat, tekevät tavalla tai toisella kahta asiaa: laskevat mahdollisia siirtovaihtoehtoja pitkälle eteenpäin, ja arvioivat matkan varrella syntyviä asemia tekemättä siirtoja. Shakkitietokoneilla voidaan siis sanoa olevan kaksi perustoimintoa, ”hakufunktio” (joka rakentaa hakupuuta eteenpäin) ja ”arviointifunktio” (joka arvioi asemia laudalla staattisesti). Kummankin toiminnon käytännön toteutukseen on useita erilaisia tapoja, joilla kaikilla on omat hyvät ja huonot puolensa.
Hakupuun rakentamisessa keskeisenä kysymyksenä on, miten tasapainotellaan puun ”leveyden” ja ”syvyyden” välillä, koska molemmat kuluttavat koneen rajallisia resursseja. Kaikkien mahdollisten siirtovaihtoehtojen tutkiminen muutamaa siirtoa syvemmälle on mahdotonta², joten jo ensimmäisistä siirroista alkaen koneen täytyy karsia leveyttä ja valita vain lupaavampia jatkoja. Siirtokandidaattien paremmuus selviää usein vasta analysoimalla peli lähes loppuun asti, joten syvyyttä analyyseihin tarvitaan myös.
Asemien arvioinnissa puolestaan täytyy löytää parhaat keinot ymmärtää aseman potentiaali ”staattisesti” ilman siirtojen laskemista eteenpäin. Perinteiset shakkiohjelmat ovat tehneet tätä arviointia ihmisen määrittelemien mallien mukaisesti tutkien esimerkiksi materiaalia ja asemallisia etuja kuten avoimia linjoja tai vapaasotilaita. Uudet tekoälyyn perustuvat ohjelmat puolestaan ovat oppineet itsenäisesti arvioimaan asemia mahdollisesti aivan erilaisilla tavoilla. Näistä lisää alempana.
(² Jos keskimääräisessä asemassa on noin 30 laillista siirtoa, on yhden siirtoparin jälkeen 1000 erilaista asemaa arvioitavaksi. Kahden siirtoparin jälkeen asemia on miljoona, ja kolmen jälkeen miljardi. Shakkitietokoneiden arviointinopeus on suuruusluokkaa 10 miljoonaa asemaa sekunnissa.)
Miten ”perinteiset” shakkitietokoneet toimivat?
Jotta voidaan ymmärtää miten AlphaZero uudisti shakkitietokoneita, täytyy ensin ymmärtää miten aiemman sukupolven enginet kuten Stockfish, Fritz ja Komodo toimivat. Perinteisten shakkiohjelmien toimintatavaksi on vakiintunut malli jossa kone rakentaa aluksi kaikista laillisista siirroista hakupuuta eteenpäin (”brute force”) siirto kerrallaan, ja arvioi puun jokaisen haaran päässä olevaa asemaa staattisesti eli katsomalla asemaa laskematta siirtoja eteenpäin. Tämä prosessi jatkuu iteratiivisesti syvemmälle niin kauan kun koneelle antaa aikaa. Matkan varrella hakupuusta karsitaan heikolta vaikuttavia jatkoja ja keskitytään vain lupaavimpiin.
Hakufunktiot
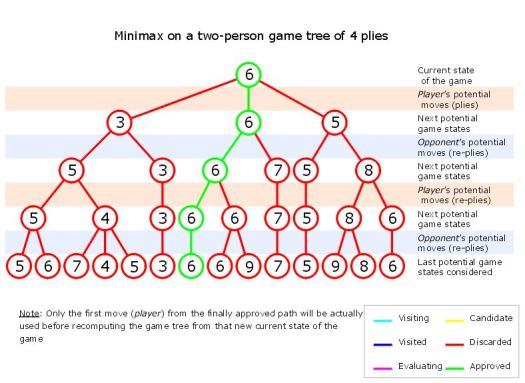
Tyypillisesti hakupuun rakentamisessa on käytetty ns. Minimax algoritmia, joka pyrkii löytämään yhden absoluuttisesti parhaan jatkon kun kumpikin pelaaja maksimoi omaa etuaan. Vaihtoehtona tälle on ns. Monte Carlo -haku, jossa (hieman yksinkertaistaen) pelataan sarja satunnaisia pelejä annetusta asemasta, ja arvioidaan sitten näiden pelien lopputuloksen perusteella eri vaihtoehtojen paremmuutta. Vaikka Monte Carlo -haku on pitkään tiedetty olevan potentiaalinen vaihtoehto shakissa, ei sen käytännön toteutusta ole saatu tehokkaaksi monista eri syistä johtuen. Mielenkiintoinen artikkeli näistä haasteista ja siitä miten AlphaZero muuttaa tilannetta löytyy täältä.
Molemmilla hakufunktioilla on omat vahvuutensa ja heikkoutensa, joihin vaikuttaa myös hakufunktion kanssa käytetty arviointifunktio. Yksi konkreettinen ero esimerkiksi on se, että Minimax algoritmi on 100% kattava eli se lähtökohtaisesti arvioi kaikki lailliset jatkot (ennen karsintaa), kun taas Monte Carlo -haku perustuu tietyllä (satunnais)logiikalla pelattujen pelien tuloksen pohjalta tehtyyn arvioon. Tässä esimerkissä Minimaxin etu on että se kykenee teoriassa löytämään lyhyellä tähtäimellä kaikki vaihtoehtoiset mahdollisuudet (ml. taktiikat), mutta ei välttämättä pysty täydellisesti arvioimaan pelin lopputulosta. Tyypillinen esimerkki on tilanne jossa loppupelin lähestyessä kone arvioi esimerkiksi laadun etumatkan +2.00 arvoiseksi, mutta asema on todellisuudessa tasapeli. Monte Carlo -haku taas onnistuu hyvin pitkän tähtäimen arvioinnissa koska se pelaa pelejä loppuun asti ja näkee miten mahdollinen etu realisoituu loppua kohden, mutta se puolestaan saattaa olla joskus sokea lyhyen tähtäimen taktiikoille jos ne eivät osu sen satunnaiseen hakufunktioon.

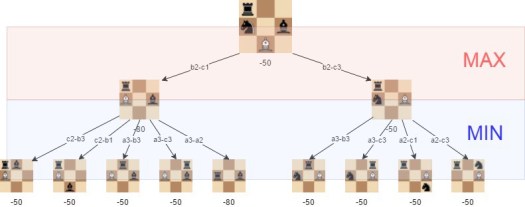
Minimax -hakualgoritmi
Perinteiset shakkitietokoneet, kuten Stockfish, Fritz ja Komodo, ovat tähän asti perustuneet lähes poikkeuksetta Minimax -algoritmiin, AlphaBeta -karsintaan ja äärimmäisen nopeiksi hiottuihin arviointifunktioihin. Nämä yhdessä mahdollistavat jopa kymmenien miljoonien asemien arvioimisen sekunnissa tehokkaalla tietokoneella. Tämä strategia on osoittautunut käytännössä toimivaksi ja sen pohjalta ovat syntyneet menneiden vuosien vahvimmat shakkitietokoneet. Minimax -algoritmissa kone käy läpi kaikkien laillisten jatkojen muodostamaa puuta, ja arvioi jokaisen vastaan tulevan aseman päättääkseen kannattaako analyysiä jatkaa kyseistä asemaa pidemmälle. Esimerkkejä Minimax -algoritmin toiminnasta alla.

Arviointifunktiot
Hakupuun edetessä syntyviä asemia arvioidaan staattisesti (eli laudalla olevaa tilannetta katsomalla, tekemättä siirtoja) arviointifunktioiden avulla. Arviointifunktion tehtävänä on siis päätellä, onko asema pelaajan kannalta edullinen ja lupaava, ja kannattaako sitä tutkia pidemmälle. Yllä olevassa esimerkissä arviointifunktion tehtävänä on siis laskea kullekin asemalle numeroarvo (”6”). Perinteisissä shakkiohjelmissa nämä arviointifunktiot on määritelty koneen ohjelmoijien ja shakin suurmestareiden yhteistyössä luomien periaatteiden mukaisesti. Arviointifunktiot (ja sitä kautta koko pelitapa) perustuvat siis pohjimmiltaan ihmispelaajien vuosisatojen aikana kerryttämään ymmärrykseen siitä miten shakkia pitäisi pelata, ja millaiset asiat tekevät asemasta vahvan tai heikon. Näiden periaatteiden pohjalta on määritelty täsmällisempiä konsepteja ja parametreja joita kone orjallisesti laskee asemia arvioidessaan, kuten esimerkiksi materiaali, avoimet linjat, kuninkaan turvallisuus, sotilasheikkoudet, vahvat ja heikot ruudut, vapaasotilaat, yms. Vaikka tämä lähestymistapa on ollut enemmän kuin riittävä ylittämään ihmisten pelitason, ei ole mitenkään selvää että ihmiskunta on onnistunut ratkaisemaan shakin salaisuutta, eli löytämään ”oikean” tavan pelata parasta shakkia. Juuri tässä piileekin se mahdollisuus johon AlphaZero iskee.
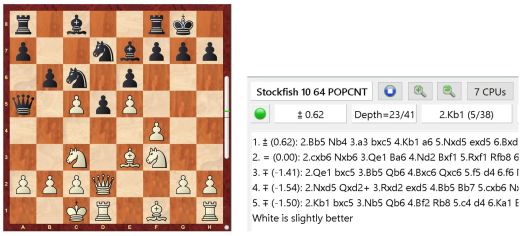
Esimerkkejä Stockfishin arviointifunktioista
![]() Stockfishin arviointifunktiot ovat täysin julkista tietoa, ja niiden toimintaan voi tutustua täällä. Laudalle voi asetella haluamansa aseman, ja nähdä alapuolelta (”Main evaluation”) mikä on Stockfishin staattinen asema-arvio. Tätä kokeillessa on siis tärkeä ymmärtää että staattisen arvion muodostamisessa ei lasketa yhtään siirtoa eteenpäin, vaan tutkitaan laudalla olevaa asemaa erilaisten ”linssien” läpi, joita on hieman yli 100 erilaista. Täydellinen lista linsseistä ja yksityiskohtainen kuvaus kunkin linssin toiminnasta löytyy sivun vasemmasta laidasta. Jokainen linssi antaa oman pistearvionsa asemasta, ja nämä pistearviot yhdistämällä sopivien painokertoimien avulla saadaan lopullinen aseman staattinen arvio. Alla on esitelty muutamia satunnaisesti valittuja esimerkkejä näistä linsseistä.
Stockfishin arviointifunktiot ovat täysin julkista tietoa, ja niiden toimintaan voi tutustua täällä. Laudalle voi asetella haluamansa aseman, ja nähdä alapuolelta (”Main evaluation”) mikä on Stockfishin staattinen asema-arvio. Tätä kokeillessa on siis tärkeä ymmärtää että staattisen arvion muodostamisessa ei lasketa yhtään siirtoa eteenpäin, vaan tutkitaan laudalla olevaa asemaa erilaisten ”linssien” läpi, joita on hieman yli 100 erilaista. Täydellinen lista linsseistä ja yksityiskohtainen kuvaus kunkin linssin toiminnasta löytyy sivun vasemmasta laidasta. Jokainen linssi antaa oman pistearvionsa asemasta, ja nämä pistearviot yhdistämällä sopivien painokertoimien avulla saadaan lopullinen aseman staattinen arvio. Alla on esitelty muutamia satunnaisesti valittuja esimerkkejä näistä linsseistä.
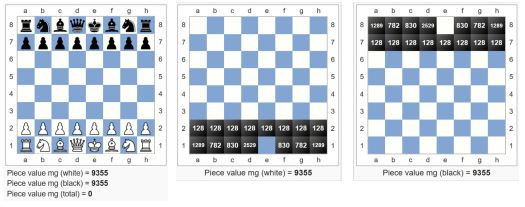
Materiaali – nappuloiden arvo (Material – Piece value middlegame)
Tämä funktio laskee laudalla olevien nappuloiden arvon, joka vaihtelee hieman riippuen siitä onko peli avausvaiheessa, keskipelivaiheessa, vai loppupelivaiheessa. Nappuloiden arvo on puhtaasti laudalla olevien nappuloiden summa, ilman mitään muuta harkintaa niiden sijainnista. Materiaalin arviointiin on käytössä myös muita funktioita jotka huomioivat materiaalin erilaista arvoa eri tilanteissa.
Vapaasotilaat (Passed middlegame)
Tämä funktio etsii laudalta vapaasotilaat (sotilaat joiden edessä tai viereisillä linjoilla ei ole vastustajan sotilaita). Vapaasotilaiden arvoa painotetaan sillä miten pitkälle ne ovat edenneet. Vapaasotilaiden arvioimiseen on käytössä myös muita funktioita jotka huomioivat eri aspekteja niiden potentiaalista.
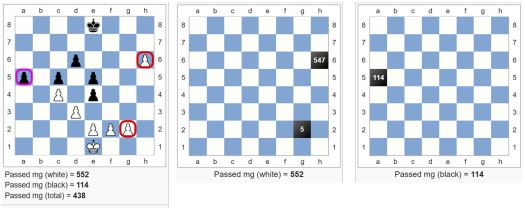
Daamin uhkaamat ruudut (Queen attack)
Tämä funktio laskee daamien uhkaamat (myös puolustamat) ruudut laudalla.
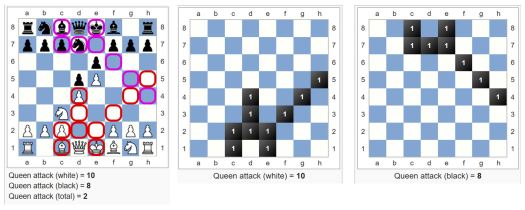
Kuninkaan suoja (Shelter strength)
Tämä funktio arvioi kuninkaan turvallisuutta sotilasaseman eheyden näkökulmasta. Kuninkaan turvallisuuden arvioimiseksi on käytössä myös useita muita funktioita.

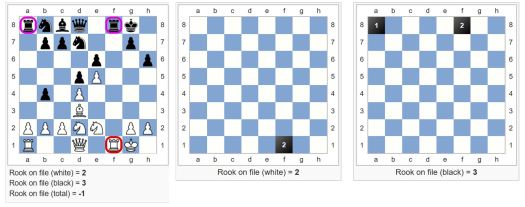
Torni linjalla (Rook on file)
Tämä funktio laskee avoimella tai puoliavoimella linjalla olevien tornien määrän.
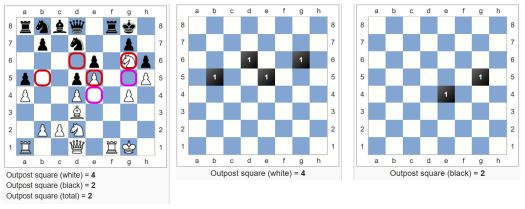
Etuvartioasemat (Outpost square)
Tämä funktio laskee niiden sotilaan suojaamien ruutujen määrän joihin pelaaja voi mahdollisesti pelata upseerinsa ilman että vastustaja pääsee sitä sotilaillaan uhkaamaan.
Pääarvio (Main evaluation)
Pääarvio on yhteenveto kaikkien eri arviointifunktioiden tuloksista. Se laskee siis hakupuussa kulloinkin pohdinnassa olevalle asemalle arvion (”+1.22”), joka palautetaan Minimax-algoritmille vertailtavaksi muiden asema-arvioiden kanssa.

Miten AlphaZero eroaa perinteisistä shakkiohjelmista?
AlphaZeron lähestymistapa shakkiin on hyvin erilainen, vaikka se pohjimmiltaan toki tekeekin täsmälleen samoja asioita kuin sen perinteiset kilpailijat: laskee mahdollisia siirtovaihtoehtoja pitkälle eteenpäin, ja arvioi matkan varrella syntyviä asemia. Tähän yhtäläisyydet päättyvätkin, sillä AlphaZeron arkkitehtuuri perustuu neuroverkon avulla toteutettuun itseopittuun arviointifunktioon ja Monte Carlo -hakualgoritmiin perinteisten Minimax-algoritmin, AlphaBeta -karsinnan ja ihmisen rakentamien arviointifunktioiden sijasta.
AlphaZero esiteltiin julkisuuteen ensimmäisenä tekoälyyn perustuvana shakkitietokoneena. Kun puhutaan ”tekoälystä”, tarkoitetaan AlphaZeron tapauksessa koneoppimista ja neuroverkkoja. Koneoppiminen on tekoälyn osa-alue, jossa toimintaa ei ole ohjelmoitu valmiiksi. Kone oppii sille annetusta datasta itsenäisesti, eikä sille määritellä toimintaohjetta jokaista erillistä tilannetta varten. Se käyttää askel askeleelta datasta oppivia algoritmeja, jolloin koneoppimisen malli kehittyy. Malli opetetaan opetusdatalla ennustamaan jotain tiettyä lopputulosta, minkä jälkeen testidata selvittää miten hyvin opetus onnistui. Tulos on sitä tarkempi, mitä enemmän mallilla on dataa käytettävissään. Neuroverkot puolestaan ovat käytännössä tiedonkäsittelyn ja laskennan malleja, joihin koneoppimisen tuloksena syntynyt ”viisaus” tallennetaan ja joiden avulla ratkaistaan uusia eteen tulevia vastaavan tyyppisiä ongelmia. Lisää tekoälystä, koneoppimisesta ja neuroverkoista löytyy esimerkiksi Wikipediasta.
AlphaZeron tapauksessa tekoälyllä viitataan siis toisaalta prosessiin, jossa se pelasi itseään vastaan 44 miljoonaa testipeliä ja kerrytti ”ymmärrystä” (käytännössä hienosääti neuroverkkonsa parametreja) siitä millaiset ratkaisut shakkipelissä ovat parempia kuin toiset, ja toisaalta taas pelien aikana käytettävään neuroverkkoihin perustuvaan asemien arviointifunktioon.
Miten AlphaZero toimii?
AlphaZeron toiminnan ytimenä on asemia staattisesti analysoiva arviointifunktio, joka on radikaalisti erilainen kuin Stockfishin ja muiden perinteisten vastaava. Sen toimintaperiaate perustuu ihmisen määrittelemien periaatteiden sijaan koneen itsensä rakentamaan ymmärrykseen shakista. Arviointifunktio antaa asema-arvion lisäksi myös järjestetyn listan todennäköisistä parhaista siirroista jatkoanalyysin perustaksi, mikä vaikuttaa merkittävästi koneen tapaan rakentaa hakupuuta eteenpäin.
Stockfishin arviointifunktio on täysin ihmisen rakentama, ja funktion tuloksena saadaan aseman potentiaalia sotilaina kuvaava numeroarvo (”+1.22”). Korkeampi luku tulkitaan aina lupaavammaksi asemaksi (mikä ei kuitenkaan automaattisesti pidä kaikissa tilanteissa paikkaansa). Tämän arvion ja muiden käytettävissä olevien tietojen perusteella koneen Alpha-Beta -algoritmi valitsee lupaavimmat asemat syvempää tutkimusta varten. Kun Stockfish esittää analyysin kuluessa arviota jostain siirrosta (”15. De6 +1.22”), tarkoittaa se käytännössä parhaaksi arvioidun jatkon viimeisenä arvioidun aseman staattista arvoa. Stockfish ei siis arvioi laudalla olevaa asemaa, vaan kertoo että parhailla mahdollisilla siirroilla (puolin ja toisin) päädytään asemaan jonka staattinen arvo on tässä esimerkissä valkealle hieman edullinen.
AlphaZeron arviointifunktio puolestaan on täysin itseoppimisen tuloksena syntynyt, eikä se sisällä mitään ihmisen antamaa tietoa. Alussa se oli tyhjä taulu, ja koneen ensimmäiset testipelit olivat täysin satunnaista (toki sääntöjen mukaista) nappuloiden siirtelyä. Satunnaisuuden keskellä syntyi (oletettavasti vahingossa) ensimmäinen matti, jolloin kone teki ensimmäisiä johtopäätöksiä siitä millaiset asiat johtavat pelaajan kannalta edulliseen lopputulokseen ja tallensi nämä tiedot neuroverkon parametreihin. Seuraavassa pelissä päästiin soveltamaan näitä oppeja uudestaan, ja vähitellen peli alkoi muistuttaa normaalia shakkia. Voisi kuvitella että ensimmäinen oivallus saattoi olla se, että jos ei syötä materiaalia, voittaa pelin helpommin. Tämä ja tuhannet muut oivallukset muokkasivat itseopiskeluprosessin aikana neuroverkon parametreja. 7 miljoonan pelin jälkeen koneen sanottiin saavuttaneen parhaiden ihmispelaajien pelitaso. Itseopiskeluprosessi jatkui 44 miljoonan pelin verran, minkä jälkeen koneen pelivahvuus oli jo ylittänyt Stockfishin tason. AlphaZero käytti tähän itseopiskeluun ainoastaan 9 tuntia. On kuitenkin hyvä muistaa että tuon 9 tunnin aikana sillä oli käytössä valtava määrä laskentatehoa (5000 1. sukupolven ja 64 2. sukupolven TPU-prosessoria).
AlphaZeron arviointifunktio on tallennettu sen neuroverkon parametreiksi. Neuroverkkojen luonteesta johtuen ei ole mahdollista katsoa arviointifunktion sisään ja yrittää ymmärtää sen toimintaa. Ei siis ole mahdollista sanoa, millaisia näkökulmia AlphaZerolla on shakkiasemien arviointiin. Voimme ainoastaan epäsuorasti yrittää tulkita AlphaZeron toimintaa katsomalla sen pelaamia pelejä (tästä lisää alempana).
AlphaZeron arviointifunktion tuloksena saadaan sekä arvio aseman potentiaalista että lista kandidaattisiirroista. Perinteisistä shakkikoneista poiketen aseman potentiaalia mitataan odotustuloksen kautta ”sotilaiden” avulla tapahtuvan pisteytyksen sijaan. AlphaZeron asema-arvio on siis esimerkiksi ”0.657”, mikä tarkoittaa 65,7% odotustulosta. Korkeampi odotustulos tarkoittaa luonnollisesti parempaa jatkoa koneen näkökulmasta. Tämän lisäksi arviointifunktio antaa listan kaikista vaihtoehtoisista siirroista, sekä alustavan todennäköisyysarvion jokaiselle siirrolle siitä että se olisi paras siirto.
AlphaZeron arviointifunktio
Alla on yksinkertainen esimerkki (lähde: Game Changer -kirja) AlphaZeron arviointifunktion toiminnasta eräässä peliasemassa ottelusta Stockfish 8:aa vastaan. Ensimmäisen kerran laudalla olevaa asemaa vilkaistuaan, AlphaZeron arviointifunktio listaa mahdolliset siirrot ja antaa jokaiselle vaihtoehdolle alustavan todennäköisyyden olla aseman paras siirto. Se myös allokoi eri variaatioille käytettävää laskenta-aikaa, jolloin lupaavimmat ja/tai mielenkiintoiset siirrot luonnollisesti priorisoidaan korkeammalle, mutta myös kummalliset vaihtoehdot tsekataan pikaisesti ettei mitään jää näkemättä. Voisi väittää että tämä on hyvin samantyyppinen logiikka kuin mitä ihmispelaajat käyttävät: intuitio kertoo mitä vaihtoehtoja asemassa kannattaisi harkita, ja sen jälkeen laskenta keskittyy lupaavimpiin vaihtoehtoihin.
Seuraavaksi arviointifunktio antaa alustavan arvion kunkin siirron odotustuloksesta, joka siis tässä vaiheessa ei vielä perustu aseman syvälliseen analyysiin useita siirtoja eteenpäin. Lopuksi arviointifunktio luo oletetun paremmuusjärjestyksen vaihtoehtoisista siirroista. On hyvä huomata miten parhaan siirron todennäköisyys, siirroille allokoitu hakuaika, arvio siirron vahvuudesta ja todennäköinen paremmuusjärjestys eivät vielä tässä vaiheessa mene aivan käsi kädessä, vaan arviot tarkentuvat analyysin edetessä. Toinen erittäin tärkeä huomio on, että aseman kokonaisarvio ei ole sama kuin minkään yksittäisen siirron arvio, vaan se lasketaan todennäköisyyslogiikan avulla painotettuna keskiarvona kaikista siirtovaihtoehdoista ja niiden arvioidusta vahvuudesta. Tässä piilee yksi merkittävä ero perinteisiin shakkikoneisiin: Stockfish arvioi siirron vahvuuden yhden ainoan molemmille pelaajille parhaaksi katsomansa linjan lopputuleman mukaan, ja olettaa että kaikki muut vaihtoehdot ovat sille edullisempia. AlphaZeron lähestymistapa puolestaan on todennäköisyyksiin perustuva ja se pyrkii arvioimaan siirtoja ottaen huomioon tulevaisuuteen ja vastustajan valintoihin liittyvän epävarmuuden.

Arviointifunktion luoman ensimmäisen asema-arvion pohjalta AlphaZero lähtee syventämään analyysiaan käyttäen Monte Carlo -algoritmia, jossa kone simuloi tietyn määrän pelejä loppuun saakka (matti/tasapeli) eri asemista ja arvioi asemien edullisuutta simuloitujen pelien tulosten perusteella. Simulointi ei tutki kaikkia variaatioita tasapuolisesti, vaan siinä painotetaan arviointifunktion antamia todennäköisempiä parhaita siirtoja kussakin asemassa. Tätä analysointiprosessia on syytä tutkia konkreettisen esimerkin kautta edellisen esimerkin asema-analyysia syventäen.
Valitaan koneen ensimmäisenä vahvimmaksi arvioima siirto 30.d5 lähtökohdaksi, ja tutkitaan miten prosessi etenee AlphaZeron ”konehuoneessa”. AlphaZero käy läpi vastustajan mahdolliset vastaukset, ja simuloi pelin mahdollista etenemistä näiden variaatioiden kautta, ottaen jokaisessa puun haarassa huomioon arviointifunktion antaman todennäköisyysjakauman aseman mahdollisista parhaista siirroista. Aluksi lupaavimmalta näyttää jatko 30.d5 exd5 31. Lxd5+ johon allokoidaan eniten analyysiaikaa.

Analyysin syventyessä AlphaZero tulee kuitenkin vakuuttuneeksi että mustalla on hyvä puolustus 30.d5 vastaan, ja arvio sen vahvuudesta alkaa laskea. Koneen huomio alkaa kiinnittyä enemmän 30.c6 siirron suuntaan, mikä saa enemmän analyysiaikaa ja sen arvio kasvaa positiivisemmaksi. Samalla analysoitavien siirtojen määrä on kaventunut jo kolmeen lupaavimpaan jotka saavat yhteensä yli 90% kaikesta prosessoriajasta.

Vielä yksi iteraatio syvemmälle, ja AlphaZeron huomio palaa jälleen siirtoon 30.d5. Se on löytänyt mielenkiintoisen linjan jossa uhrataan vielä yksi sotilas tummaruutuisen lähetin herättämiseksi eloon, ja käyttää nyt 90% kapasiteetistaan tämän linjan tutkimiseen. Itse pelissä päädyttiin lopulta siirtoon 30.d5 jonka odotustulokseksi arvioitiin 0.735, ja lupaavin variaatio tätä päätöstä tehdessä oli 30.d5 exd5 31.Ld3 c6 32.Dc3 Tf7 33.Tg1 Dg7 34.Dc2 Kf8 35.b6 d4 ja niin edespäin.
Tämä esimerkki auttaa hieman ymmärtämään miten AlphaZeron arviointifunktio toimii, ja erityisesti miten se mahdollistaa ”intuitionsa” avulla syvemmän analyysin keskittymisen nopeasti lupaavampiin variaatioihin, mikä on tärkeää koska neuroverkkoon perustuva arviointifunktio on monta kertaluokkaa raskaampi laskennallisesti. Se myös kertoo siitä miten AlphaZero arvioi asemia todennäköisyysjakaumien kautta, kun taas Stockfishin arvio perustuu puhtaasti yhden lupaavimmaksi uskotun variaation arvoon. Lopuksi AlphaZero arvioi asemia odotustuloksen kautta, ja analysoidessaan simuloi pelejä hamaan loppuun asti, minkä ansioista se esimerkiksi kykenee usein arvioimaan erilaisten loppupelien pitkäaikaisen potentiaalin paremmin kuin Stockfish. Kääntöpuolena taas on riski siitä että AlphaZero ”missaa” lyhyen tähtäimen taktiikoita, koska sen intuitio ei ohjaa sitä analysoimaan jokaista epäloogisen näköistä siirtoa kuten Stockfish tekisi.
Lisätietoa AlphaZeron toiminnasta löytää esimerkiksi tästä chess.com artikkelista. Yksi näkökulma AlphaZeron Monte Carlo -hakualgoritmiin löytyy puolestaan täältä. Tärkeä lähde lisätiedolle on luonnollisesti myös alkuperäinen artikkeli AlphaZeron julkaisijoilta.
AlphaZeron vaikutukset perinteisiin shakkiohjelmiin
AlphaZero sai välittömästi myös perinteisten shakkiohjelmien tekijät vakuuttuneeksi uuden teknologian tuomista mahdollisuuksista. Kuluneen vuoden aikana on syntynyt täysin uusia AlphaZeron inspiroimia shakkiohjelmia, ja myös perinteisiin shakkiohjelmiin on tullut useita merkittäviä muutoksia AlphaZeron innoittamana.
Leela Chess Zero
 Tunnetuin uusi hanke on Leela Chess Zero (”Lc0”), joka toimii hyvin samalla logiikalla kuin AlphaZero. Lc0:n taustalla on Stockfishin kehittäjänä tunnettu Gary Linscott, joka pian AlphaZeron julkistuksen jälkeen näki neuroverkkojen potentiaalin shakissa ja ryhtyi kehittämään AlphaZeron ”kotiversiota”. Lc0 ja sen eri variantit ovat jo osoittautuneet erittäin vahvoiksi ja ovat pelivahvuudeltaan jo hyvinkin Stockfishin veroisia. Lc0 on ilmainen ja vapaasti ladattavissa kotikoneelle käytettäväksi omassa shakkiohjelmassa. Lc0 ja muut neuroverkkoihin perustuvat shakkiohjelmat vaativat tehokkaan näytönohjaimen pyörittämään neuroverkon laskentaa.
Tunnetuin uusi hanke on Leela Chess Zero (”Lc0”), joka toimii hyvin samalla logiikalla kuin AlphaZero. Lc0:n taustalla on Stockfishin kehittäjänä tunnettu Gary Linscott, joka pian AlphaZeron julkistuksen jälkeen näki neuroverkkojen potentiaalin shakissa ja ryhtyi kehittämään AlphaZeron ”kotiversiota”. Lc0 ja sen eri variantit ovat jo osoittautuneet erittäin vahvoiksi ja ovat pelivahvuudeltaan jo hyvinkin Stockfishin veroisia. Lc0 on ilmainen ja vapaasti ladattavissa kotikoneelle käytettäväksi omassa shakkiohjelmassa. Lc0 ja muut neuroverkkoihin perustuvat shakkiohjelmat vaativat tehokkaan näytönohjaimen pyörittämään neuroverkon laskentaa.
Fat Fritz
 Myös muut perinteisten shakkiohjelmien kehittäjät ottavat askeleita AlphaZeron viitoittamalla polulla. ChessBase on julkaissut maksullisen Fat Fritz -version suositusta Fritz-enginestään. Fat Fritz toimii pääpiirteittäin samalla logiikalla kuin AlphaZero, ja se perustuukin Lc0:n teknologiaan ja ChessBasen kustomoituun neuroverkkoon jota on ”opetettu” kaikella ihmiskunnan shakkitietämyksellä avausteoriasta pelitietokantojen kautta loppupelitietokantoihin (mikä saattaa olla hyvä tai huono asia – aika näyttää). Myös Fat Fritz on osoittanut vahvuutensa, voittaen Stockfish 8:n 100 pelin ottelussa 62,5-37,5, ja Stockfish 10:n niin ikään 100 pelin ottelussa 52,5-47,5.
Myös muut perinteisten shakkiohjelmien kehittäjät ottavat askeleita AlphaZeron viitoittamalla polulla. ChessBase on julkaissut maksullisen Fat Fritz -version suositusta Fritz-enginestään. Fat Fritz toimii pääpiirteittäin samalla logiikalla kuin AlphaZero, ja se perustuukin Lc0:n teknologiaan ja ChessBasen kustomoituun neuroverkkoon jota on ”opetettu” kaikella ihmiskunnan shakkitietämyksellä avausteoriasta pelitietokantojen kautta loppupelitietokantoihin (mikä saattaa olla hyvä tai huono asia – aika näyttää). Myös Fat Fritz on osoittanut vahvuutensa, voittaen Stockfish 8:n 100 pelin ottelussa 62,5-37,5, ja Stockfish 10:n niin ikään 100 pelin ottelussa 52,5-47,5.
Komodo
 Komodon uusin 13.2 -versio sisältää myös joitain AlphaZeron inspiroimia uudistuksia. Näkyvin näistä on Monte Carlo -haku, jonka avulla Komodon väitetään löytävän uusia aiempaa luovempia tapoja jatkaa peliä eri asemista. Komodon arviointifunktio on kuitenkin edelleen perinteinen, eikä se perustu neuroverkkoihin kuten esim. Lc0 ja Fat Fritz.
Komodon uusin 13.2 -versio sisältää myös joitain AlphaZeron inspiroimia uudistuksia. Näkyvin näistä on Monte Carlo -haku, jonka avulla Komodon väitetään löytävän uusia aiempaa luovempia tapoja jatkaa peliä eri asemista. Komodon arviointifunktio on kuitenkin edelleen perinteinen, eikä se perustu neuroverkkoihin kuten esim. Lc0 ja Fat Fritz.
Yhteenveto
Palataan siis vielä hetkeksi kappaleen alkuperäiseen kysymykseen. Mitä konkreettista uutta AlphaZero toi shakkitietokoneiden maailmaan, joka mahdollisti välittömästi nousun koneiden kuninkaaksi? Vastaus kaikessa yksinkertaisuudessaan on tämä: Ihmisen ajattelumalleista täysin vapaan tavan arvioida shakkiasemia ja tehdä valintoja parhaista siirroista. AlphaZero ei ole kahlittu ihmispelaajien todennäköisesti epätäydellisiin tapoihin tehdä shakista ymmärrettävää tai pelattavaa, vaan se on luonut itse oman ymmärryksensä siitä mikä on parasta. Se myös luottaa toiminnassaan osittain ”intuitioon”, siinä missä perinteiset ohjelmat toimivat ainoastaan raa’an työn voimalla. Todistuksena tämän uuden tavan valtavasta potentiaalista näemme myös perinteisten ohjelmien kehittyvän nopeasti tähän suuntaan.
Tekoälyn esiinmarssin tuloksena olemme nähneet paitsi murskaavia tuloksia myös maagisen hienoja pelejä ja shakillisia oivalluksia jotka johdattavat meidät seuraavan kysymyksen ääreen: mitä me ihmispelaajat voimme oppia shakista katsomalla AlphaZeron pelitapaa?
2. Voiko AlphaZero tarjota ihmispelaajille uusia strategisia ideoita ja muuttaa ihmisten käsitystä parhaasta tavasta pelata shakkia?
Ensireaktiot AlphaZeron peleistä Stockfishiä vastaan olivat häkeltyneitä. AlphaZero ei ainoastaan voittanut Stockfishiä täysin ylivoimaisesti, vaan sen pelityyli oli jotain aivan ennennäkemätöntä jopa koneiden maailmassa: erittäin dynaamista, innovatiivista, räiskyvää, brutaalia. Sen peleissä on havaittavissa huomattavasti joustavampaa suhtautumista materiaalin, tilan, ajan ja aktiviteetin kaltaisiin käsitteisiin ja niiden suhteisiin. AlphaZero vaikuttaa olevan valmis uhraamaan yhtä tai useampaa näistä elementeistä paljonkin saadakseen etua toisaalla. Edun ei edes tarvitse olla välitön mattihyökkäys, vaan puhtaasti asemallinenkin etu voi olla AlphaZeron mielestä sotilaan tai parin arvoinen. Avauksissa AlphaZero on kehittänyt itseoppimisvaiheen aikana selkeästi oman repertuaarinsa (on hyvä muistaa että AlphaZeron käytössä ei ole ollut avauskirjastoja, ei itseoppimisvaiheessa eikä pelien aikana). Yksi mielenkiintoinen esimerkki on se, että AlphaZero pelaa valkeilla yksinomaan 1.d4 (joskus siirtovaihdoin 1.Rf3), sillä se näkee että 1.e4 e5! ei anna valkealle riittävästi etua avauksessa. AlphaZeron peleissä on myös löydettävissä useita strategisia ja taktisia ideoita jotka toistuivat pelistä toiseen.
AlphaZeron pelit
AlphaZeron ensiesiintyminen tapahtui joulukuussa 2017, kun se kohtasi Stockfish 8:n 100 pelin ottelussa. Koneilla oli käytössään hieman erilaista rautaa, mikä tekee vertailun todellisesta pelivahvuudesta hieman vaikeaksi. Myös ottelun säännöt ja peliajat olivat sellaiset että ne eivät välttämättä olleet molemmille koneille yhdenvertaiset.
Ottelu pelattiin varsin nopealla 1 minuutti/siirto -miettimisajalla, ilman avauskirjastoja. Stockfish 8:n käytössä oli 64 prosessoriydintä, mutta vain 1 GB välimuistia (hashtable). Näistä syistä Stockfishin on sanottu olleen selvästi normaalia pelitasoaan heikompi. AlphaZerolla oli käytössään ainoastaan 4 TPU-prosessoria (verrattuna itseoppimisvaiheessa käytössä olleisiin 5000 + 64 TPU-prosessoriin).
Ensimmäisen ottelun lopputulos oli joka tapauksessa tyrmäävä. AlphaZero voitti 28 peliä (25 valkeilla, 3 mustilla), ja loput 72 peliä päättyivät tasan. Stockfish ei siis kertaakaan onnistunut selviämään pelistä voittajana. Chess.com on kirjoittanut kattavan artikkelin ensimmäisistä peleistä. Kaikki ensimmäisen ottelun pelit löytyvät ladattavana pgn-tiedostona: alphazero_vs_stockfish_all.
Ensimmäisen ottelun jälkimainingeissa koneet pelasivat vielä 12 sadan pelin ottelua valikoiduista ihmispelaajien suosimista avausvariaatioista. Näistä peleistä AlphaZero voitti 290 ja Stockfish 24, muiden 886 pelin päättyessä tasan.
Ensimmäisten otteluiden synnyttämän kritiikin jälkeen AlphaZero ja Stockfish (nyt versio 9) kohtasivat uudessa 1000 pelin ottelussa vuoden 2018 loppupuolella. Tällä kertaa miettimisaikana oli 3 tuntia + 15sek/siirto. Stockfishin käytössä oli 44 prosessoriydintä, 32 GB välimuisti (hashtable), ja loppupelitietokanta. Ottelun lopputulos näytti kuitenkin jälleen, että valta on vaihtunut: AlphaZero voitti 155 peliä, ja Stockfish vain 6. Peleistä 839 päättyi tasan. Chess.com julkaisi artikkelin toisesta ottelusta. Artikkelissa myös linkkejä videoanalyyseihin mielenkiintoisimmista peleistä, sekä linkki 20 mielenkiintoisen pelin pgn-tiedostoon.
AlphaZeron avausrepertuaari
Itseoppimisvaiheessa AlphaZero pelasi hyvin satunnaisia avauksia, koska sillä ei ollut mitään ennakkotietoa siitä miten shakkipeli kannattaisi aloittaa. Vähitellen avaukset alkoivat kuitenkin muistuttaa ihmispelaajillekin tuttuja avauksia ja variaatioita. Itseoppimisvaiheen (9 tuntia) ajalta on julkaistu mielenkiintoinen tilasto eri avausten esiintymistaajuudesta kun koneen pelivahvuus kehittyy.
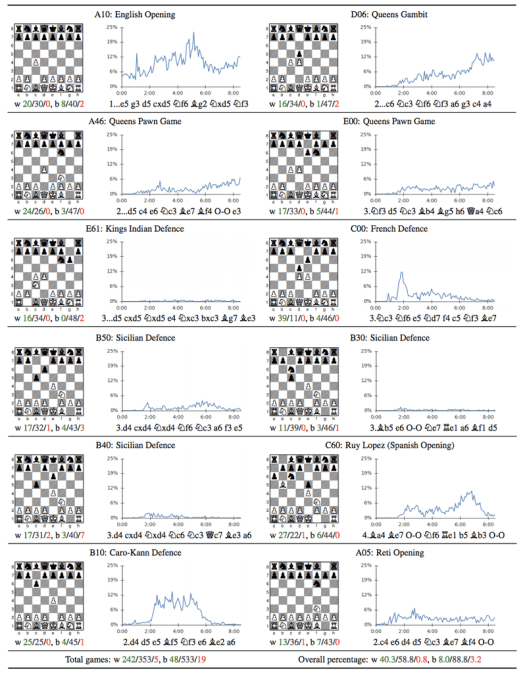
Itseopiskelun alkuvaiheessa AlphaZero vaikutti pelaavan paljon Englantilaista (1.c4), kunnes se noin kahden tunnin jälkeen ”löysi” siirron 1.e4 ja sen myötä ensin Ranskalaisen ja pian sen jälkeen Caro-Kannin puolustuksen. Sisilialainen ei missään vaiheessa ole ollut AlphaZeron suosiossa mustan vastauksena 1.e4 -siirtoon. Vähitellen myös Espanjalainen alkoi kiinnostaa AlphaZeroa, ja siitä tulikin myöhemmin sen päävastaus valkean 1.e4 -siirtoon. Itseopiskelun edetessä AlphaZero tuli kuitenkin enemmän ja enemmän vakuuttuneeksi siitä, että 1.d4 (tai siirtovaihdoin 1.Rf3) on valkean paras tapa avata, mikä näkyy myös myöhemmin varsinaisissa otteluissa Stockfishin kanssa. Mustan vastauksista suosituimpia vaikuttaa olevan torjuttu daamigambiitti ja erilaiset d5-e6-Rf6 -tyyppiset struktuurit, kun taas esimerkiksi kuningasintialainen ja Grunfeld eivät herättäneet itseopiskeluvaiheessa juuri lainkaan AlphaZeron mielenkiintoa.
AlphaZeron pelejä tutkimalla voidaan todeta, että sen avauskäsittely on hyvin klassisten periaatteiden mukaista: keskustan hallinta ja upseerien kehittäminen on aina prioriteettina. Avausvalikoima edustaa hyvin tunnettuja avauksia ja niiden päämuunnelmia. Valkeilla AlphaZero pelaa lähes poikkeuksetta 1.d4, ja avaa joskus myös 1.Rf3. Se ei koskaan pelaa 1.e4, koska arvioi vastauksen 1. … e5 erittäin vahvaksi mustalle. Mustilla AlphaZero vastaa 1.e4:ään aina 1. … e5, minkä jälkeen peli jatkuu joko Berliinillä (ei koskaan 3. … a6), tai Italialaisena 3. … Rf6 tai 3. … Lc5. Mustilla AlphaZero vastaa 1.d4 siirtoon lähes poikkeuksetta 1. … Rf6, jatkaen 2.c4 e6 3.Rf3 d5 4.Rc3 Lb4.
Avauksissa piilee ensimmäinen AlphaZeron mahdollinen mullistus shakkimaailmaan. Kun aikaa kuluu ja ihmispelaajat pääsevät laajemmin analysoimaan avauksia AlphaZeron tai sen ”jälkeläisten” avulla, onkin mielenkiintoista nähdä, mitä vaikutuksia sillä on eri avausten suosioon. Vaikka onkin selvää että mikään kone ei voi kertoa lopullista totuutta eri avausten paremmuudesta, herättää AlphaZeron näkökulma taatusti kiinnostusta tutkia avauksia uusin silmin, ja mahdollisesti muuttaa painotuksia hieman eri variaatioihin.
AlphaZero ja ”0.00”
Usein kuulee pelaajien keskustelevan avausten ja pelien analysoinnista koneen avulla, ja kommenttina on että ”tämä variaatio on pelkkää nolla-nollaa”. Toisin sanoen, Stockfish tai muu perinteinen kone arvioi että asema on täysin tasan, eikä kummallakaan pelaajalla ole mahdollisuutta ”paeta” tasapeliä. Tällainen arvio on helppo hyväksyä tilanteessa jossa materiaali on käymässä vähiin tai kummallakaan pelaajalla ei ole mahdollisuuksia murtautua toisen asemaan. Hämmentävää on kuitenkin se, että koneet usein saattavat näyttää ”nolla-nollaa” asemissa joissa ihmispelaajan näkökulmasta kaikki on avoinna, asema on erittäin monimutkainen, ja molemmilla pelaajilla on hyviä mahdollisuuksia haastaa vastustaja koko pisteen arvoisesti. Miksi näissä tilanteissa kone helposti arvioi aseman ”0.00:ksi”? Ovatko koneet kyvyttömiä löytämään (asemallisia) etuja, ovatko ne haluttomia ottamaan riskiä, vai ovatko ne mestareita löytämään jokaisessa asemassa jonkin pakottavan siirtojen toiston mikä tappaa pelin välittömästi?
AlphaZeron peleistä löytyy yksi erittäin mielenkiintoinen aspekti: siinä missä Stockfish toistuvasti arvioi asemia ”0.00:ksi”, AlphaZero onnistuu konvertoimaan niitä voitoksi. Se näkee mahdollisuuksia horjuttaa tasapainoa ja rakentaa pieniä asemallisia etuja joista mahdollisesti kumuloituu suurempia ja konkreettisempia etuja. Se arvioi usein nämä asemat itselleen positiiviseksi, kun Stockfish on jo tuominnut pelin ”nolla-nollaksi”. Game Changer -kirjassa esitellään muutamia erityyppisiä esimerkkejä näistä tilanteista.
”0.00 vs. hiipivät hyökkäykset”

Eräässä AlphaZeron ja Stockfishin välisistä peleistä oli päädytty valkean (AlphaZero) 18. siirron jälkeen oheiseen asemaan. Valkealla on tilaetua ja vahva sotilas e5:ssä. Enemmistö valkean upseereista tähyää mustan kuningasaseman suuntaan, kun taas mustan upseerit ovat hieman vähemmän aktiivisia. Valkealla on selvästi edellytyksiä kuningashyökkäykseen, kun taas mustan täytyy etsiä vastapeliä daamisivustalta. Stockfish ja muut perinteiset koneet arvioivat aseman kuitenkin ”0.00” päätyen useimmiten jonkinlaiseen siirtojen toistoon. Koneiden suosittelemat linjat eivät myöskään vastaan ihmispelaajan näkemystä valkean kuningashyökkäyksestä ja mustan vastapelistä daamisivustalla. AlphaZero kuitenkin arvioi tämän aseman valkealle 66.5% voittavaksi, eli valkean etu on selkeä. Pelin edetessä AlphaZero kehittelee määrätietoisesti hyökkäystään kuningassivustalla, kun Stockfish vaikuttaa lähinnä epäröivän ja siirtelevän nappuloitaan päämäärättömästi.

Ihmispelaajan näkökulmasta valkea on edistynyt merkittävästi omassa suunnitelmassaan, kun taas mustan asema on hädin tuskin muuttunut lähtötilanteesta. AlphaZero arvioi aseman valkealle jo 82.5% voittavaksi, kun Stockfish edelleen lähtee liikeelle ”0.00” arviosta ja hieman pidempään pohdittuaan antaa valkealle 0.27 verran etua. Peli päättyi lopulta 73. siirrossa valkean voittoon. Stockfish ei nähnyt tulevaa vaaraa ajoissa, ja antoi AlphaZeron rakentaa ”hiipivää hyökkäystään” kaikessa rauhassa.
”0.00 vs. avoimet linjat”

Toisessa esimerkissä on päädytty asemaan joka on täynnä mahdollisuuksia. Mustalla on kaksi sotilasta enemmän, mutta sen upseerit ovat sidottuja puolustamaan asemaa valkean hyökkäykseltä, ja sotilasasema on täynnä reikiä. Jälleen Stockfish ja muut perinteiset koneet arvioivat aseman ”0.00:ksi”, jopa useiden hyvin erilaisten jatkojen jälkeen. Toiset koneet pyrkivät pitämään aseman suljettuna, kun taas toiset uskaltavat rohkeasti avata asemaa ja pakottaa tasapelin tavalla tai toisella. AlphaZero kuitenkin on optimisti ja löytää asemassa mielenkiintoisen tavan vastata mustan bxa3 -siirtoon Ka2:lla, jonka jälkeen valkea jatkaa vahvojen upseerien ja avoimien linjojen avulla mustan painostamista ja lopulta voittaa pelin. Jälleen loistava esimerkki siitä miten perinteisten koneiden kyky nähdä aseman potentiaalia on rajoittunut.
Näiden esimerkkien pohjalta voidaan todeta toinen AlphaZeron shakkimaailmaa mahdollisesti mullistava ominaisuus: se kykenee näkemään potentiaalia pelata voittoa asemissa joissa perinteiset koneet ”pakenevat” tai luulevat voivansa paeta pakottavaan tasapeliin. AlphaZero onnistuu houkuttelemaan perinteiset vastustajansa asemiin joissa ne eivät vielä haista vaaraa, ja kun ne vihdoin huomaavat vastustajan olevan vahvoilla, on jo liian myöhäistä reagoida. Ihmispelaajan näkökulmasta tämä avaa uusia mahdollisuuksia tutkia avauksia ja asemia koneen kanssa: ei ole syytä hylätä Stockfishin ”nolla-nolla” -jatkoa, vaan kannattaa itse paneutua näihin asemiin, pohtia miksi kone arvioi aseman näin ja miettiä onko ihmispelaajan näkökulmasta sittenkin mahdollisuuksia löytää etua ja jopa pelata voittoa.
AlphaZeron pelillisiä erityispiirteitä
AlphaZeron pelejä läpikäymällä on löytynyt erilaisia ihmispelaajan silmin havaittavia toistuvia teemoja, joita voisi kuvailla sen pelityylin elementeiksi. On vaikeaa sanoa hahmottaako AlphaZero peliä näiden ”linssien” läpi (johtuen siitä että sen neuroverkon sisältöä ei ole mahdollista analysoida), mutta ne auttavat ihmispelaajia ymmärtämään edes hieman mitkä tekijät ovat korkealla sen arviointifunktiossa. Alla on tiivistetty lista havaituista teemoista, tarkempia yksityiskohtia löytyy mainiosta Game Changer -kirjasta.
- AlphaZero rakentaa mielellään suoria uhkauksia vastustajan kuningasta kohtaan, pyrkii rajoittamaan vastustajan kuninkaan liikkumavapautta ja pyrkii pitämään oman kuninkaansa suojassa uhkauksilta
- AlphaZero varmistaa keskustan joko sulkemalla aseman tai muuten kontrolloimalla keskustaa, ennen hyökkäyksen käynnistämistä sivustalla.
- AlphaZero uhraa usein 1-2 sotilasta pelin alkuvaiheessa avatakseen linjoja ja diagonaaleja vastustajan kuninkaan suuntaan. Tehokkaimmat hyökkäykset perustuvat usein avoimen linjan ja diagonaalin yhteistyöhön.
- AlphaZero suosii ratsujen etuvartioasemia (outposts) ja on valmis uhraamaan aikaa ja materiaalia saadakseen ratsut näihin ruutuihin
- AlphaZero rajoittaa tehokkaasti vastustajan upseereiden aktiivisuutta, tarvittaessa jopa uhraamalla materiaalia. Se voittaa usein pelejä saamalla yhden tai useamman vastustajan upseerin passiiviseksi, ja vaihtamalla sen jälkeen kaikki aktiiviset upseerit pois
- AlphaZero puolustautuu usein hämmentämällä asemaa taktisempaan suuntaan ja luomalla vastauhkauksia, kun taas Stockfishin tapa on pyrkiä pitämään puolustusasema kasassa kaikin keinoin tarkkaan laskemalla
- AlphaZero ei kiirehdi avoimien linjojen valtaamista torneilla, vaan keskittyy tarvittaessa mieluummin parempien linjojen avaamiseen ja säästää avoimet linjat myöhempää käyttöä varten
- AlphaZero käyttää tehokkaasti hyväkseen upseereidensa aktiivisuutta. Erityisesti, se on tehokas avaamaan ”toisen rintaman” uhkauksille kun vastustajan upseerit on sidottu puolustamaan ensimmäistä heikkoutta.
- AlphaZero onnistuu usein puristamaan vastustajan erittäin ahtaaseen puolustusasemaan, ja sen jälkeen löytämään uhrausten avulla keinon murtaa puolustus.
- AlphaZero pelaa usein h2-h4-h5-h6 -tyyppisiä laitasotilaan etenemisiä, eikä yleensä lyö g6:een vaan mieluummin rajoittaa vastustajan kuninkaan liikkumavaraa h5-h6:lla.
- AlphaZero pyrkii usein hallitsemaan toisen värisiä ruutuja ja rakentamaan hyökkäystä niiden kautta. Tämä saavutetaan usein eriväristen lähettien tilanteessa.
- AlphaZero linnoittautuu usein eri puolelle kuin vastustaja saadakseen mahdollisuuksia aggressiiviseen kuningashyökkäykseen.
- AlphaZero välttää systemaattisesti joitakin ihmispelaajille tyypillisiä strategisia teemoja, esimerkiksi vähemmistöhyökkäystä ns. Carlsbad -struktuurissa.
Useat näistä teemoista on ihmispelaajalle tuttuja, kuten esimerkiksi keskustatilanteen stabilointi ennen sivustahyökkäykseen ryhtymistä. Muutamat teemoista ovat ehkä hieman uusia, tai ainakin uudesta näkökulmasta ihmispelaajille. Esimerkiksi linjojen ja diagonaalien yhteistyö hyökkäyspelaamisessa, tai vastustajan upseerin pakottaminen paitsioon eivät ole ihan tyypillisimpiä tapoja kuvata ihmispelaajien ajatuksia. Näiden yleisen tason teemojen voidaankin sanoa olevan kolmas mahdollinen shakkimaailmaa mullistava aspekti AlphaZeron peleissä. Ne herättävät uusia kysymyksiä keskipelin strategisista suunnitelmista ja inspiroivat ajattelemaan materiaalia, tilaa, aikaa ja aktiviteettia uudella tavalla.
Yhteenveto
Palataan jälleen hetkeksi toisen kappaleen alkuperäiseen kysymykseen: voiko AlphaZero tarjota ihmispelaajille uusia strategisia ideoita ja muuttaa ihmisten käsitystä parhaasta tavasta pelata shakkia? Selvää on että verrattuna perinteisiin shakkiohjelmiin, AlphaZeron pelitavassa on monia uusia elementtejä joita myös ihmispelaajien on mahdollista soveltaa analyyseissaan ja käytännön peleissään. Avausteoria tulee epäilemättä kehittymään kun vanhoja muunnelmia päästään tutkimaan uudentyyppisen koneen avustuksella. Monista ”nolla-nollaksi” tuomituista asemista saattaa löytyä aivan uutta potentiaalia kun niitä tutkitaan AlphaZeron ja sen jälkeläisten avustamana. Monia AlphaZeron peleissä nähdyistä strategisista ja taktisista motiiveista tullaan epäilemättä näkemään myös ihmisten välisissä peleissä jatkossa. Lienee siis kohtuullista sanoa että AlphaZero varmuudella haastaa ihmispelaajia näkemään asioita uudella tavalla ja sitä kautta vähitellen mullistaa lajia jatkossakin.
3. Mitkä ihmispelaajien käytännön ongelmat ovat edelleen ratkaisematta ja mitä ratkaisuja shakkitietokoneet voisivat tulevaisuudessa tarjota?
Samalla kun suuri shakkia pelaava yleisö ihailee koneiden alati kasvavaa pelivahvuutta ja uusia entistä monipuolisempia pelitapoja, on syytä myös pohtia kehityksen kääntöpuolta. Miten koneiden pelivahvuuden kohoaminen 3500 tasolta kohti 4000 tasoa auttaa ihmispelaajia käytännön pelien analysoinnissa, avausten tutkimisessa ja peleihin valmistautumisessa? Onko jonkin aseman ”absoluuttisen totuuden” löytymisellä käytännön merkitystä ihmispelaajalle? Mitkä ihmispelaajien käytännön ongelmat ovat edelleen ratkaisematta ja mitä ratkaisuja shakkitietokoneet voisivat tulevaisuudessa tarjota?
Ihmispelaajan tarpeet liittyen shakin ymmärtämiseen, omien shakkitaitojen kehittämiseen ja tuleviin peleihin valmistautumiseen ovat hyvin erilaiset ja paljon monipuolisemmat kuin mihin mikään shakkitietokone, uusi tai vanha, pystyy tällä hetkellä vastaamaan. Ihmispelaaja tarvitsee erittäin rajallisen laskentakykynsä tueksi abstraktimpaa ymmärrystä asemasta, sen luonteesta ja potentiaalista. Ihmispelaajan tulee myös huomioida se että vastassa on toinen epätäydellinen ihmispelaaja, mikä avaa paljon käytännön mahdollisuuksia pelata muunnelmia jotka koneiden maailmassa ovat heikompia tai jopa täysin pelikelvottomia.
Mitä shakkitietokoneet itse asiassa tekevät?
Hieman yksinkertaistaen, shakkitietokone pystyy vastaamaan vain ja ainoastaan yhteen kysymykseen: ”Mikä on paras siirto tässä asemassa, olettaen että vastustaja tekee ainoastaan parhaita siirtoja?” Tätä kysymystä kannattaa pysähtyä miettimään hetkeksi. Se ei ole lainkaan niin triviaali kuin äkkiseltään kuulostaisi. Shakkitietokoneet osaavat ainoastaan etsiä parasta mahdollista siirtoa, olettaen vastustajan tekevän ainoastaan parhaita mahdollisia siirtoja. Parhaan mahdollisen määrittelee tässä luonnollisesti koneen oma pelitaso, eli se olettaa itse tietävänsä parhaat siirrot molemmille ja etsii niiden puitteissa itselleen suotuisinta jatkoa.
On siis tärkeää huomata että kone ei esimerkiksi koskaan lähde jatkoon jossa menestyminen vaatisi vastustajan virhettä. Ihmispelaaja taas useinkin saattaa ”bluffata” eli viedä peliä sellaiseen suuntaan (esim. erittäin monimutkaiseen taktiseen asemaan tai tietyn tyyppiseen loppupeliin), jossa uskoo vastustajansa tekevän helpommin ratkaisevan virheen. Kone taas hylkää välittömästi jatkon joka olisi 99,99% jatkoista voittava, mutta tarjoaa vastustajalla 0,01% mahdollisuuden jos löytää 10 äärimmäisen tarkkaa siirtoa yksi toisensa jälkeen. Kone siis olettaa vastustajaltaan täydellistä tarkkuutta ja virheetöntä peliä.
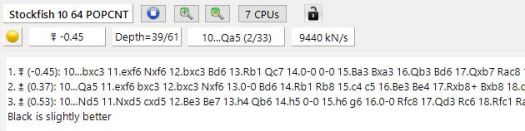
Shakkitietokoneen arvion lisäksi shakkiohjelmat (kuten ChessBase, Fritz, Komodo) tarjoavat pelaajalle erilaisia tietokantoihin perustuvia lisätietoja, kuten avauskirjastoja, pelitietokantoja ja loppupelitietokantoja. Näiden avulla ihmispelaaja (miksei myös tietokonekin) voi rakentaa omaa avausrepertuaariaan, tai analysoida laudalla olevia asemia aiempaan analyysiin ja tutkimukseen perustuen. Valitettavasti myöskään tietokannat eivät anna vastauksia kysymykseen ”miksi”. Avausten osalta ne hieman paikkaavat shakkitietokoneen heikkouksia kertomalla eri siirtojen odotustuloksia käytännön peleissä.
Käytännössä shakkiohjelmien ja -tietokoneiden rooli rajoittuu näihin kahteen asiaan, jota ne luonnollisesti tekevät äärimmäisellä tarkkuudella ja tehokkuudella, ja joka saa niiden pelivahvuuden lähentelemään jo 4000 ELO-pisteen rajaa. Voisi kuitenkin väittää että tämä pelivahvuuden kasvu ei enää pitkään aikaan ole palvellut ihmispelaajien käytännön tarpeita läheskään parhaalla mahdollisella tavalla.
Mitä shakkitietokoneet eivät tee?
Ihmispelaajien näkökulmasta shakkitietokoneilla on useita selkeitä puutteita, mikä rajoittaa niiden hyötyä käytännön shakinpelaamisessa, tai ainakin tekee niiden tehokkaasta hyödyntämisestä erittäin paljon työläämpää kuin olisi tarpeen.
Ensinnäkin, strategisella tasolla kone ei osaa kertoa ihmispelaajalle pelin isoa kuvaa, ja minkälaisia strategisia suunnitelmia olisi syytä laatia. Taitava ihmispelaaja osaa välittömästi kertoa aloittelijalle esimerkiksi että ”olet edellä kehityksessä ja upseerisi ovat hyvissä asemissa, nyt on aika lähteä rohkeaan kuningashyökkäykseen”, tai että ”vastustajasi on ottamassa d-linjaa hallintaansa ja tulee rakentaman voittavan hyökkäyksen ellet estä sitä”. Shakkitietokoneet kertovat kyllä parhaan siirron asemassa, mutta eivät osaa vastata ihmispelaajan peruskysymykseen ”miksi” julistaessaan jonkin siirron parhaaksi. Ihmispelaajan ensimmäinen reaktio on ymmärtää, miksi joku ehdotettu siirto olisi hyvä, tai mahdollisesti paras. Mikä suunnitelma siirron takana on? Mitkä asemalliset seikat puoltavat tämän suunnitelman valintaa? Mitä mahdollisia vastauksia vastustajalla on valittavana? Mitä taktisia kuvioita siirron toteuttaminen jatkossa sisältää? Miksi joku toinen ihmiselle luonnollisen näköinen siirto ei ole lainkaan ehdotettujen joukossa? Pelaaja voi itse etsiä vastausta näihin kysymyksiin tutkimalla manuaalisesti variaatioita eteenpäin, mikä on luonnollisesti erittäin työlästä eikä silti usein anna vastauksia joita ihminen kaipaisi.
Toiseksi, perinteiset enginet osaavat pelata ainoastaan ”täydellistä” vastustajaa vastaan. Ne eivät osaa ottaa huomioon vastustajan epätäydellisyyttä. Ne eivät koskaan tee siirtoja jotka vaatisivat vastustajan erehtymistä. Jos vastustaja pystyy kumoamaan jonkin siirron tekemällä 10 peräkkäistä ainoaa siirtoa, kun yksikin harha-askel johtaisi häviöön, toteaa kone tämän jatkon pelikelvottomaksi, eikä se näy koneen ehdottamissa vaihtoehdoissa. On helppo havaita että ihmispelaajan näkökulmasta tämä on suuri puute, koska kyseinen jatko olisi todennäköisesti erittäin vahva käytännön pelissä.
Kolmanneksi, koneet ovat edelleen huonoja kertomaan tutkimiensa jatkojen ”kriittisyydestä” pelaajan omasta näkökulmasta, eli miten paljon pelaajan tulee löytää täydellisiä siirtoja jatkossa jotta peli pysyisi kasassa. Joissain jatkoissa tilanne säilyy rauhallisena ja pelaajalla on useita tapoja jatkaa peliä pienin eduin ilman että tasapaino suuresti järkkyy lyhyellä tähtäimellä. Toisissa jatkoissa taas pelaajan tulee löytää hyvin tarkasti useita yksittäisiä siirtoja, tai muuten asema romahtaa välittömästi. Tämä tieto on ihmispelaajalle kriittinen, mutta sen saa selville nykyisillä koneilla vain tutkimalla variaatioita manuaalisesti eteenpäin siirto kerrallaan.
Neljänneksi, shakkitietokoneet kertovat arvionsa valittavien siirtojen suhteellisesta paremmuudesta, mutta eivät yleensä osaa kertoa mitään pelin lopputuloksen mahdollisesta jakaumasta. Jos aseman arvioidaan olevan tasan, olisi ihmispelaajan kannalta mielenkiintoista tietää, perustuuko tämä arvio siihen että toisella pelaajalla on pakottava siirtojen toisto jolla peli päättyy 100% varmuudella tasan, vai että peli on täysin auki ja kummallakin pelaajalla on 50% mahdollisuus voittaa peli, mutta asema-arvio on ”dynaamisesti tasan”. Tähän asiaan löytyy toki tilastotietoa avaustietokannoista, mutta näiden tilastojen luotettavuus ja hyödyllisyys on todellisuudessa heikko¹ ja vähenee entisestään pelin edetessä kohti tutkimattomia vesiä. Juuri julkaistu Fat Fritz on ensimmäinen ohjelma joka tarjoaa analyysinsa tueksi myös arvion pelin lopputulosjakaumasta, mutta sen luotettavuudesta tai käytännön hyödystä ei ole vielä kokemusta.
(¹ Avaustietokannoissa mainitaan että jonkin siirron odotustulos on esimerkiksi 45%, eli musta pärjää hieman valkeaa paremmin. Tämä ei kuitenkaan ota huomioon pelaajien vahvuuslukuja, joka usein selittää tulosten jakaumaa enemmän kuin valittu siirto. Esimerkkinä tästä on vaihtoslaavi jossa eri asemissa valkean lyönti cxd5 näyttää useissa asemissa tilastojen valossa mustalle edulliselta. Kun tilastoja katsoo tarkemmin, huomaa että tämä siirto esiintyy usein peleissä joissa mustilla pelaava pelaaja on selkeästi vahvempi, jolloin valkeilla pelaava pyrkii vaihdon avulla kuivattamaan pelin tasapeliksi, mutta ei siinä kuitenkaan aina onnistu. Lyönti d5:een tuskin siis antaa mustalle etua, vaikka tilastot näin osoittavatkin.)
Näiden esimerkkien lisäksi on varmasti lukuisia muita puutteita, joita eri ihmispelaajat kaipaisivat opiskelun, valmisteluiden tai analyysin tueksi.
Mitä shakkitietokoneet voisivat tehdä?
Edellä on kuvattu useita ihmispelaajan kannalta ratkaisemattomia kysymyksiä, joihin shakkitietokoneilla voisi olla hyvät mahdollisuudet antaa vastauksia. Alla on esitelty muutamia kirjoittajan laatimia ehdotuksia hypoteettisten esimerkkien avulla siitä miltä seuraavan sukupolven shakkitietokone voisi näyttää ihmispelaajan näkökulmasta.
Asema-analyysi
Ensimmäinen hyödyllinen toiminto voisi olla ihmispelaajan näkökulmista toteutettu visuaalinen analyysi laudalla olevasta asemasta, joka korostaisi aseman erityispiirteitä ja antaisi ihmispelaajalle vinkkejä suunnitelman tekemiseen. Esimerkkinä alla asema tyypillisestä Sisilialaisella puolustuksella alkaneesta pelistä. Jokainen kokenut pelaaja osaisi kertoa toiselle pelaajalle aseman perusominaisuuksista. Pelaajat ovat linnoittautuneet eri puolille, joten on odotettavissa molemminpuolinen kilpajuoksu vastustajan kuninkaan kimppuun. Valkealla on vahva ote c1-h6 -diagonaalista, tilaa edetä sotilaillaan kuningassivustalla, mahdollinen vahva ruutu d5:ssä ja painetta d-linjaa pitkin kohti d6-sotilasta. Mustalla puolestaan on puoliavoin c-linja, mahdollisuus edetä daamisivustan sotilaillaan, ja toisaalta hieman ahtaasti sijoittunut tummaruutuinen lähetti sekä d6-sotilaan heikkous puolustettavanaan. Jos shakkiohjelma osaisi kertoa ihmispelaajalle aseman ominaisuuksista vastaavin tavoin, olisi siitä varmasti paljon hyötyä.

Mahdolliset suunnitelmat
Toinen asia jossa kone voisi auttaa ihmispelaajaa on vaihtoehtoisten suunnitelmien hahmottaminen pelin edistämiseksi (toista ihmispelaajaa vastaan). Hypoteettinen esimerkki suunnitelmien esittämisestä sanallisessa muodossa alla.

Jatkojen ”kriittisyys”
Kolmas hyödyllinen toiminto voisi olla kuvaus siitä, miten useita kriittisiä (=ainoita) siirtoja ehdotettuun variaatioon sisältyy. Käytännön analyysissa kone hylkää kaikki jatkot joista löytyy yksikin vastustajalle edullinen variaatio, riippumatta siitä miten vaikeaa sen löytäminen ihmispelaajalle olisi. Alla esimerkki pelistä Vallejo Pons – Keinänen, 1.11.2019.
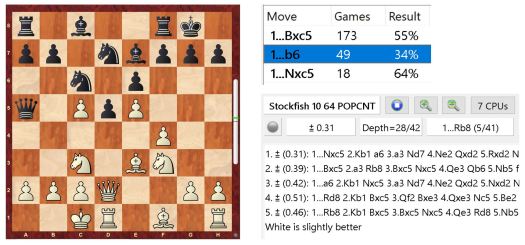
Tässä asemassa kone arvioi mustan parhaaksi jatkoksi 10. … Nxc5 valkean pienin eduin. Pelitietokannan mukaan kuitenkin mustan siirto 10. … b6 on ollut mustalle tulosten valossa suosiollinen (Result 34% tarkoittaa että valkea on saanut keskimäärin 0.34 pistettä peleistä mustan jatkaessa b6). Mistä tämä ristiriita johtuu? Kun tarkastellaan mahdollisia jatkoja siirron 10. … b6 jälkeen, huomataan että valkean on löydettävä useita tarkkoja siirtoja välttääkseen asemansa välittömän romahduksen. Mikäli valkea löytää kaikki nämä siirrot (kuten pelissä kävi), päädytään asemaan jossa valkealla on kohtuullinen etu. Siirron b6 vahvuus onkin siinä että se antaa valkealle useita erehtymisen mahdollisuuksia, joita hyvin valmistautunut mustilla pelaava pelaaja voi välittömästi hyödyntää. Muutama näistä kriittisistä valinnoista esimerkkinä alla.


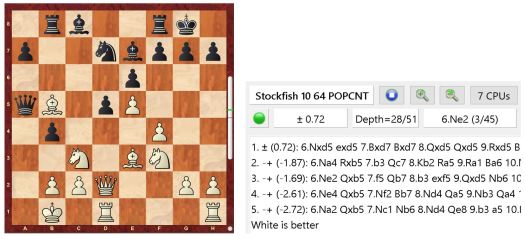
Palataan vielä hetkeksi esimerkin alkuasemaan ennen mustan 10. … b6 siirtoa. Kone ei näe tätä siirtoa vahvaksi, koska se löytää helposti yllä kuvatun jatkon jonka jälkeen valkean asema on hyvä. Mustilla peliin valmistautuva ihmispelaaja voisi kuitenkin mielellään valita tämän jatkon, jos uskoisi että vastustaja ei sitä tunne. Erehtymisen mahdollisuus valkeilla on ilmeinen ja mustan etu merkittävä mikäli valkea ei löydä tarkimpia siirtoja. Shakkitietokone voisi hyvin auttaa ihmispelaajaa näiden kriittisten jatkojen löytämisessä huomattavasti nykyistä paremmin. Hypoteettinen esimerkki alla.

Siirtojen odotustulosjakauma
Neljäs hyödyllinen toiminto voisi olla ehdotettujen siirtojen odotettu lopputulosjakauma. Käytännössä siis kone arvioisi sitä, millä todennäköisyydellä peli päättyy kummankin pelaajan voittoon tai tasapeliin. Kun nykyisellään koneet arvioivat aseman olevan ”0.00” tai hyvin lähellä sitä, se ei vielä kerro automaattisesti onko kyseessä staattinen vai dynaaminen tasa-asema. Sama tilanne on uusilla koneilla jotka arvioivat asemia odotustuloksen kautta. Mikäli jonkin siirron odotustulos on ”62%”, olisi ihmisen kannalta tärkeää ymmärtää onko kyseessä erittäin tasainen asema jossa valkealla on pieniä mahdollisuuksia pelata voittoa, vai onko peli täysin avoin ja kumpi tahansa voi voittaa, valkean päätyessä hieman useammin paremmalle puolelle.
Uudet Monte Carlo -algoritmiin perustuvat koneet tekevät jo tähän tarvittavaa pelien simulointia, mutta summaavat lopputuloksen yhdeksi arvioksi odotustuloksesta (”62%”), joka vielä usein shakkiohjelmassa käännetään ”sotilaiksi” (”+0.38”), jotta arviot olisivat paremmin verrattavissa perinteisten engineiden arvioihin. Tieto odotustulosjakaumasta olisi siis suhteellisen helposti tuotettavissa erityisesti uusilla shakkiohjelmilla.
Uusi Fat Fritz on juuri julkaissut tämän toiminnallisuuden, eli käyttäjän on mahdollista nähdä perinteisen analyysin lisäksi koneen arvio pelin odotustulosjakaumasta.
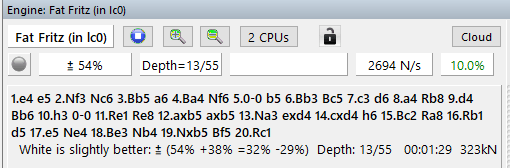
Analyysi ”omaa vastustajaa vastaan”
Viides hyödyllinen toiminto voisi olla sellainen, jossa koneelle annetaan lähtötiedoksi oman tulevan pelin vastustajan pelivahvuus ja/tai muita arvioita pelitaidoista (kuten esimerkiksi asemallinen tai taktinen pelitaito). Koneelle voisi myös antaa listan vastustajan peleistä analysoitavaksi. Kone voisi tämän perusteella arvioida, minkä tyyppiset avaukset tai asemat saattaisivat olla ko. vastustajalle helppoja tai vaikeita, ja korostaa analyysissaan sen mukaisia jatkoja. Aiemmista peleistä kone voisi myös helposti ja automaattisesti kaivaa tulevan vastustajan systemaattisia virheitä (esim. tietyn avauksen käsittelyssä), ja nostaa esille mahdollisuudet hyödyntää niitä tulevassa pelissä.
Yhteenveto
Palataan vielä kerran kappaleen alkuperäiseen kysymykseen: Mitkä ihmispelaajien käytännön ongelmat ovat edelleen ratkaisematta ja mitä ratkaisuja shakkitietokoneet voisivat tulevaisuudessa tarjota? Ylläolevan perusteella voidaan todeta, että shakkitietokoneet kehittyvät valtavalla vauhdilla, mutta vain hyvin kapealla rintamalla (=absoluuttinen pelivahvuus toista ”täydellistä” pelaajaa vastaan), ja ne ovat hyvin rajoittuneita kyvyissään auttaa ihmispelaajia ymmärtämään, kehittymään, valmistautumaan ja analysoimaan pelejään toisia ihmispelaajia vastaan. Ehdotetun kaltaiset, ihmispelaajaa käytännön peleissä auttavat toiminnallisuudet, ovat hyvinkin mahdollisia toteuttaa engineiden ja käyttöliittymien toimintaa muokkaamalla. Nähtäväksi jää milloin shakkiohjelmien kehittäjät siirtävät huomionsa tämän tyyppisiin asioihin. Juuri nyt valtaosa kehittäjien resursseista menee todennäköisesti uuden neuroverkkoteknologian hiomiseen käyttövalmiiksi. Ehkäpä seuraavien vuosien aikana näemme myös ihmispelaajia enemmän hyödyttäviä toiminnallisuuksia shakkiohjelmissa.
Loppusanat
Mullisitko ”tekoäly” shakkimaailman? Vain aika näyttää millä tavoin uusien shakkitietokoneiden tuomia mahdollisuuksia voidaan hyödyntää shakkimaailmassa laajemmin. Tähänastiset peliesitykset antavat vahvaa uskoa siihen että tulevaisuuden tehokkaimmat enginet ovat AlphaZeron ja Leela Chess Zeron tapaan ”vapaita” ihmisten rajoitteista ajatella shakkia. Luvassa on todennäköisesti yhä mielikuvituksellisempia tapoja pelata shakkia kun koneet löytävät yhä uusia ihmispelaajan käsityskyvyn tuolla puolen olevia ideoita ja suunnitelmia. Nämä oivallukset varmasti muokkaavat vähitellen myös ihmispelaajien ajatuksia pelistrategiasta ja epäilemättä monipuolistavat ihmispelaajien avausvalikoimaa merkittävästikin.
Voidaan kuitenkin väittää, että suurempi mullistus ihmispelaajien näkökulmasta antaa kuitenkin edelleen odottaa itseään, sillä koneiden ja niiden kehittäjien painopiste ei ole ollut ihmiselle relevanttien kysymysten ratkaisemisessa. Edellytyksiä näiden kysymysten ratkaisemiseen luonnollisesti on, ja ratkaisujen sisällyttäminen shakkiohjelmiin ei välttämättä ole kovin suuri tai monimutkainen tehtävä. Kyse ei ole niinkään shakkiohjelmien pelivahvuuden kehityksestä, vaan siitä miten niiden luomaa ”ymmärrystä” paketoidaan ihmiselle relevanttiin muotoon.
Seuraavaa mullistusta odotellessa, keskittykäämme nauttimaan meneillään olevan mullistuksen tuomasta viihteestä ja inspiraatiosta!
Juha Patosalmi, shakkiharrastaja
Artikkeli julkaistu EtVaSin nettisivulla 21.11.2019
Artikkelin lähteenä ja inspiraationa käytetty mainittujen materiaalien lisäksi erityisesti Game Changer -kirjaa (Sadler, Regan, 2019)

Hei,
Hieno ja ehdottomasti syvimmälle menevä suomen kielellä kirjoitettu artikkeli tietokoneshakin nykytilasta. Harvinaista objektiivista otettakin löytyy, vaikka mainitsetkin lähteeksi A0:n promootiokirjan. Artikkelissa on monia keskustelua herättäviä aiheita, joita kaikkia en pysty tähän tiivistämään.
A0-SF-otteluista: On selvää, että ottelun lähtökohdat eivät olleet reilut. Miksi muuten järjestää suuria AI-promootioita kuten AlphaGo vs. ihminen ottelut? Tiimi tiesi satavarmasti, että tulee voittamaan murskaavasti. Shakkiottelun tapauksessa närkästystä herätti Stockfish:n raudan specsit ja yli vuoden vanhan virallisen #8 version käyttö, kun (~40 self-eloa) vahvempi kehitysversio olisi ollut tarjolla ottelun aikaan. Maallikolle ytimien suuri määrä näytti ehkä vahvalta, mutta todellisuudessa ne olivat heikkoja AMD:n Opteron prossuja ja niille 1 GB hash-muistia suorastaan vitsi. Lisäksi 100-pelin ottelun julkaistut pelit voivat olla täysin mielivaltaisesti valikoituja, ja 100 peliä engine-engine-otteluissa on tilastollisestikin erittäin riittämätön otanta virheen ollessa ~70 eloa suuntaansa.
Sama kaava toistui myös muissa pelatuissa peleissä. 1000 pelin ottelusta ”joitakin pelejä” julkaistiin, ja SF hävisi myös ”vahvalla” avauskirjalla. Vähänkin tietokoneshakista ymmärtävä tajuaa, että tulokset ovat liian hyviä ollakseen täysin puolueettomia. Mitä todennäköisesti tapahtui oli, että enginet toistivat samoja avauksia, joita A0 voitti säännöllisesti. Jos SF olisi pelannut oikeasti vahvalla voittamiseen optimoidulla kirjalla, A0 olisi hävinnyt tämän osa-ottelun. Vähän kuin panisi pantiksi koko ihmiskunnan shakkitietämyksen vs. alkutekijöissään oleva koneäly. Tässäkin mielestäni valittiin avauslinjoja, joissa kirja jätti SF:n pulaan enemmän kuin voitti pelejä.
Sinänsä DeepMind saavutti näissä demonstraatioissa konseptitodistuksen (proof of concept) oppivien neuroverkkojen soveltuvuudesta mitä erilaisimpien ongelmien tutkimiseen, ja tietenkin paikkasi shakkitietämystä monella alueella. Ihan neljässä tunnissa ei tietenkään noustu nollasta parhaaksi shakkimoottoriksi, vaan taustalla on vuosien ja vähintään miljoonien dollareiden kehitystyö jo pelkästään TPU:den (Tensor Processing Unit) luomiseen. DeepMind esimerkiksi palkkasi tiimiinsä M. Lain, joka oli kehittänyt oman 2400 engine-elon neuroverkkopohjaisen Giraffe-moottorin vuonna 2015.
Se, mitä neuroverkot (NN) A0:n myötä paransivat perinteisiin alpha-beta-moottoreihin verrattuna on asemien totuudenmukaisempi arviointi, mikä perustuu laajalti hyvien ja huonojen sotilasrakenteiden tunnistamiseen. Tässä voisi löyhästi puhua ’asemallisen shakin’ (positional chess) kumouksesta, mutta mitään tarkkoja määritelmiä ’asemalliselle’ ja ’taktiselle’ shakille ei ole esitetty, sillä ne ovat aina jossain suhteessa läsnä jokaisessa tilanteessa. Upseerin voi usein palauttaa takaisin lähtöruutuun seuraavalla siirrolla (pieni virhe) mutta sotilasta ei (peruuttamaton virhe). Ja parhaat enginet eivät anna mitään anteeksi…
Yksi käytännön huomio on, että NNt pelaavat avaukset paljon paremmin kuin alpha-betojen ihmisten tekemät (hand crafted eval, HCE) funktiot, kun niille ei anneta avauskirjaa. Toinen huomio konepeleissä on thorn pawn:ien luominen, missä esim. valkean sotilas ajetaan ruutuun h6, ja mustalla on sotilaat h7:ssa ja g6:ssa. Tätä manööveriä vastaan perinteiset enginet eivät usein ole osanneet puolustaa menestyksellä. MCTS+NN-engineiden tyyliä kutsutaan toisinaan asemien ’generalisoimiseksi’, mikä toisinaan muistuttaa positionaalista boa-kuristusta. Ollessaan johdossa NNt pitävät asemallisen edun,siirtelevät upseereita päämääräämättömästi (shuffle) useita siirtoja, ja välillä etenevät sotilaalla välittämättä vastapuolen (taktisista) siirroista. Kun etua on tarpeeksi, ei minkään tyyppisellä vastapelillä pysty estämään voittoa. Ehkä tämä piirre on ällistyttävintä, mitä neuroverkot ovat tuoneet uutena shakkiin. Tosin alpha-betojen vahvistuessa NNt ovat alkaneet missaamaan taktisia vaihtoja ja uhrauksia. Näin ollen NN:n tietämys ja tekniikka eivät ole absoluuttinen totuus miten shakkia ’pitäisi’ pelata.
Mutta paljon on ehtinyt tapahtua A0-SF-ottelun 2017 ja artikkelin kirjoitushetken 21.11.2019 jälkeen. LC0-tiimi on ratkaissut monia DeepMindin julkaisuissa aukkoja jättäneitä ongelmia (salaisuuksia!?), saanut moottorin toimimaan ’melko tehokkaasti’ normaaleilla (mutta kalleimmilla cuda-NN tukevilla) kuluttajanäytönohjaimilla ja noussut ainakin NN:n osalta vahvemmaksi kuin A0 aikanaan. Tässä on mainittava samalla LC0:n suurin heikkous: skaalautuvuus GPU:den suhteen. Käsitykseni mukaan LC0 on stabiili 4 GPU:n rinnakkaisajoon asti, kun standardi SF pyörii 512 CPU:lla (maksimi on tällä hetkellä 4096 säiettä). LC0:n vahvuus kärsii myös kun sille annetaan liikaa CPU:ta. Liekö syynä MCTS vai mystisten TPU:den puute… ? Löysikö DeepMindikaan tähän ratkaisua. Epäilemättä tulee Deep Blue-analogia mieleen: tehoton haku (ja arviointi), mutta riittävä määrä spesiaaliprossuja hoitaa homman kotiin.
Elokuussa 2020 perinteisille alpha-beta-moottoreille tuli joulu: puhtaasti CPU:lla ajettava NN-arviointi kehitettiin SF:lle. NNUE (Efficiently Updatable Neural Networks) kehitettiin alunperin SF-pohjaisille shogi-moottoreille vuonna 2018. SF:n vahvuus kasvoi heti kättelyssä ~100 self-eloa. Mutta oleellisempaa on, että se on paikannut juuri niitä heikkouksia, joita ei ole osattu HCE:llä toteuttaa.
Mutta mitä neuroverkot tarkalleen ottaen tekevät asemien arvioinnissa? Ne ovat laskettuja matriiseja hienostuneiden algoritmien mukaisesti yhteen suuntaan. Komodon tekijä M. Lefler kuvaa neuroverkkoja tällä hetkellä mustiksi laatikoiksi: ne täytyisi osata takaisinmallintaa (reverse engineer), jotta niistä voitaisiin saada konkreettisia asioita irti (eli käytännössä pystyä luomaan HCE :-)). Itse kutsuisin verkkoa approksimaatioksi koko pelikirjasta: avaus-, keskipeli- ja loppupeli-. Sitähän se haun avustuksella on jo valmiiksi lasketuista alkuarvoista…
Ovatko NNt virheettömiä arvioijia? Eivät yksinkertaisesti ole. Molemmat LC0 ja hybridi SF NNUE arvioivat vielä suhteellisen yksinkertaisia torni- ja ocb-loppupelejä väärin. 80% odotusarvo/voittotodennäköisyys, joka vastaa 1.4 sotilaan etua konvertoituna koneotteluissa ei ainakaan minulle anna lisäarvoa näkemättä tilannetta laudalla tai arviointihistoriaa.
Ihmispelaajien vertaaminen tai yhdistäminen engine-tyyppiseen pelaamiseen on jonkin tyyppistä vainoharhaista fantasiaa, josta ei olla haluttu päästää irti. Kun preppauksesi päättyy siirtonumeroon X etkä voi transponoida mitenkään preppaukseesi, niin silloin todella olet omillasi. Tylymmin sanottuna sekä alpha-beta- ja NN-moottoreiden taso on niin musertava, että parhaimmatkaan ihmispelaajat eivät voi emuloida niitä muutamaa siirtoa enempää. Lisäksi LC0:n tyyli pelata on ihmisille käytännössä mahdoton kopioida taikka opettaa paitsi tietenkin opettelemalla siirtoja ulkoa.
Muuttavatko NNt käsitystä parhaasta shakista? Eivätpä juuri. Kirjeshakissa (ICCF) tasapelikuolema on ollut jo vuosia läsnä, että shakin sääntöjä ja pisteytystä on ehdotettu jo vaihdettaviksi. Tietokonepeleissä ja -analyyseissä joitakin aiemmin huonoja linjoja ollaan havaittu olevan pelastettavissa, ja toisia, jotka ovatkin häviäviä koneen jauhaessa siirtoja. (Melkeinpä tähän lähtökohtaan perustuvat tärkeimmät nykyiset tietokoneshakkikilpailut TCEC ja CCC).
Ihmisten välinen ero mitataan jossain muussa kuin noudattamalla neuroverkkojen ehdottamaa strategiaa tai laskemalla papuja alpha-betojen tapaan laudan ääressä. Nykyiset huippupelaajat pelaavat liikaa kapeita, turvallisia ja ulkoa opeteltuja avauksia toisiaan vastaan eikä riskin ottoa juuri näy. Kun vastassa on 2600-luokan pelaaja, otetaan riskimpi variaatio ja näin bluffataan voittoa itselle. Ehkäpä ääripäitä edustavat parhaiten Caruana, joka voi pelata 30 preppaussiirtoa saavuttaen jo voittoaseman, jos engine jatkaisi loppuun. Mutta kun se preppaus loppuu, konversio on liian vaikea ihmistaidoille ja peli päätyy tasan. Toisena on tietenkin Carlsen, jonka tyyli näyttää täysin päinvastaiselta mihin muut saman sukupolven pelaajat ovat pyrkineet. Hän pelaa avaukset pragmaattisesti ja yrittää saada vastustajat nopeasti pois preppauksesta. Ja kun yleiset pelitaidot ja mentaalinen kestävyys ovat kertaluokkaa tai kahta vastustajaa paremmat keski- ja loppupelissä niin lopputuloskin on mitä on. Luulenpa, että Garrylla on ollut osansa tämän tyylin iskostajana.
3. osion ehdotukset ovat unelmointia ja mahdottomia toteuttaa edes etäisesti ;). Epätäydellistä pelaajaa on mahdoton ennakoida, vaikka loisitkin malleja perustuen vastustajan pelaamiin peleihin. Millä todennäköisyydellä saat vastustajan pelaamaan tiettyä avausta (esim. Albinin vastagambiittia) ja siinä pakottamaan tai toivomaan vastustajan virhettä siirrossa 4. e3? (Laskerin ansa)?
Jotain visuaalista ’vaarallisuus’- ja ’taktisuus’-mittaristoa oli tarjolla Fritz 13 käyttöliittymään saakka (https://uscfsales.wordpress.com/2012/02/14/fritz13s-chess-dashboard-the-measurements-display/). Se, mihin funktioihin ne tarkalleen perustuvat ovat tietenkin Ch€$$basen omaisuutta. Apua niiden luomiseen voi kysyä talkchessistä tai TCEC:n chatista/ discordista.
PS.
Nykyistä shakin tasoa ja saatavuutta kaikilla rintamilla on paljolti kiittäminen avoimuuteen ja avoimeen lähdekoodiin perustuvia yhteisöjä kuten Stockfish, LC0, talkchess.com, TCEC ja lichess.org muutamia mainitakseni.
Viime aikoina on käynyt aukottomasti ilmi, että Houdini 5, Houdini 6 ja Fire (privaattiversiot) moottorit ovat klooneja Stockfish (8):sta pienin modauksin. Sinänsä tämä ei ole yllätys, sillä molemmat olivat alkujaankin Rybka-klooneja.
Astetta tuoreempi GPL-rikkomus (tai ainakin epäselvyys) liittyy Chessbasen Fat Fritz-moottoreihin. Fat Fritz 1 on LC0 klooni pienin muutoksin ja Fat Fritz 2 on SF NNUE klooni samaan tapaan:
https://lichess.org/blog/YCvy7xMAACIA8007/fat-fritz-2-is-a-rip-off
https://www.chess.com/news/view/chessbase-fat-fritz-2-stockfish-leela-chess-zero
Se, että näillä softilla rahastetaan 100€ kun erot ovat olemattomia, ei anneta krediittiä alkuperäisille tekijöille ja vielä kehdataan luoda bullshit PR-tarinoita, miten klooni voittaa alkuperäisen on jotain käsittämätöntä ja epäkunnioittavaa todellisia open-source neroja kohtaan. Vähintään pitäisi kyseenalaistaa käyttää tällaisten huijareiden softaa, mutta tämä ei ole ainoa likainen tapaus alalla. Mutta maallikko ei ajattele muuta kuin kaupallinen vs. ilmainen: kaupallisen on pakko olla laadukkaampi tuote no matter what…
– Fishcooking
TykkääTykkää
Kiitos paljon erinomaisesta vastauksesta! Jos aiheen pohdinta kiinnostaa enemmänkin, ota yhteyttä etvas@shakki.net ja voimme vaihtaa ajatuksia lisää!
TykkääTykkää